
Jina Code Embeddings 1.5B represents a breakthrough in code understanding technology. This model transforms how developers search through codebases, retrieve relevant code snippets, and build intelligent developer tools. Unlike traditional text embeddings that struggle with programming syntax and semantics, this specialized model understands code across more than 15 programming languages.
What Makes This Model Special?
The model builds on the Qwen2.5-Coder-1.5B foundation, which Jina AI has fine-tuned specifically for software development workflows. Think of it as a translator that converts both natural language questions and code snippets into mathematical representations (vectors) that capture their meaning. When you ask, “How do I read a CSV file in Python?” the model can find relevant code even if the documentation uses different words like “parse” or “load” instead of “read.”
Core Capabilities
The model excels at five key tasks:
-
Text-to-Code Retrieval: You describe what you want in plain English, and the model finds matching code. For example, searching for “function to calculate factorial recursively” will locate appropriate implementations even if they use different variable names or slightly different logic.
-
Code-to-Code Similarity: Compare two code snippets to see if they do the same thing, regardless of styling differences. This helps identify duplicate code, find similar implementations, or suggest refactoring opportunities.
-
Code-to-Documentation: Generate or find natural language explanations for code blocks. When you encounter an unfamiliar function, the model helps you understand what it does without reading every line.
-
Code Completion: Given a partial code snippet, the model predicts what should come next. This powers intelligent autocomplete features in modern code editors.
-
Technical Question Answering: Answer programming questions by matching them with relevant documentation, Stack Overflow answers, or code examples from your codebase.
Flexible Vector Dimensions
One of the most innovative features is the Matryoshka embedding support. The model produces 1536-dimensional vectors by default, but you can truncate these to 128, 256, 512, or 1024 dimensions with minimal accuracy loss. This flexibility matters tremendously for production systems.
Consider a scenario where you’re building a code search engine for a large company. Storing 1536-dimensional vectors for millions of code snippets requires significant memory and slows down searches. By truncating to 256 dimensions, you reduce storage by 83% and speed up similarity calculations by roughly 6x, while retaining most of the search quality. You adjust this tradeoff based on your specific needs.
Technical Architecture Details
The model uses several advanced techniques to achieve high performance:
-
FlashAttention-2 Optimization: Traditional attention mechanisms in transformer models consume quadratic memory relative to sequence length. FlashAttention-2 reorganizes computations to use the GPU’s memory hierarchy more efficiently, enabling longer sequences and faster inference. When you process a 10,000-token code file, FlashAttention-2 can be 3-5x faster than standard attention.
-
Last-Token Pooling: To convert a sequence of token embeddings into a single vector, the model uses the last token’s representation. The tokenizer pads sequences on the left (unlike most language models that pad on the right), ensuring the last token always contains meaningful information about the entire input.
-
Extended Context Window: With support for 32,768 tokens (roughly 25,000 words), you can embed entire source files, API documentation pages, or even small codebases in a single operation. This eliminates the need to chunk large documents and lose context across boundaries.
Hardware Requirements and Recommendations
Choosing the right hardware depends on your use case. Let’s break down different scenarios:
Entry-Level Setup (8-16GB VRAM)
Suitable For: Individual developers, small projects, experimentation
If you’re just testing the model or building a personal code search tool, an RTX 3060 with 12GB or a cloud T4 instance works fine. You’ll process one or two queries at a time with sequences up to 8,000 tokens. This setup handles typical development workflows like searching your own projects or building a small RAG (Retrieval-Augmented Generation) system.
Limitations: Processing large batches will be slow. If you need to embed thousands of documents, expect it to take hours rather than minutes.
Standard Production Setup (16-24GB VRAM)
Suitable For: Production services, medium-sized teams, API endpoints
An RTX 4090 or cloud L4 instance with 24GB VRAM provides the sweet spot for most applications. You can batch 8-16 queries together and handle sequences up to 16,000 tokens efficiently. This configuration supports a small team’s code search needs or powers a moderate-traffic API endpoint.
Performance: Expect to process hundreds of embeddings per minute, making it viable for real-time search as developers type queries.
Professional Setup (40-48GB VRAM)
Suitable For: Large-scale retrieval systems, high-concurrency services
With an A100 40GB or L40S 48GB GPU, you enter enterprise territory. Batch sizes of 32-64 queries with full 32k token sequences become practical. This setup serves multiple teams simultaneously or indexes massive codebases (millions of files) within reasonable timeframes.
Use Cases: Company-wide code search, large-scale code analysis, multi-tenant SaaS products.
Enterprise Setup (80GB+ VRAM)
Suitable For: Research institutions, very large organizations, specialized applications
A100 80GB or H100 GPUs handle extreme workloads. You can process very long documents (entire modules), maintain multiple model instances for redundancy, or serve hundreds of concurrent users. Most organizations won’t need this tier unless handling exceptional scale.
Detailed Installation Process Using Spheron Network
We’ll walk through setting up the model on a GPU-powered virtual machine using Spheron’s decentralized compute platform. Spheron offers affordable GPU resources, powered by both data center-grade infrastructure and community nodes, providing flexibility in cost and performance.
Step 1: Access Spheron Console and Add Credits
Head over to console.spheron.network and log in to your account. If you don’t have an account yet, create one by signing up with your Email/Google/Discord/GitHub.
Once logged in, navigate to the Deposit section. You’ll see two payment options:
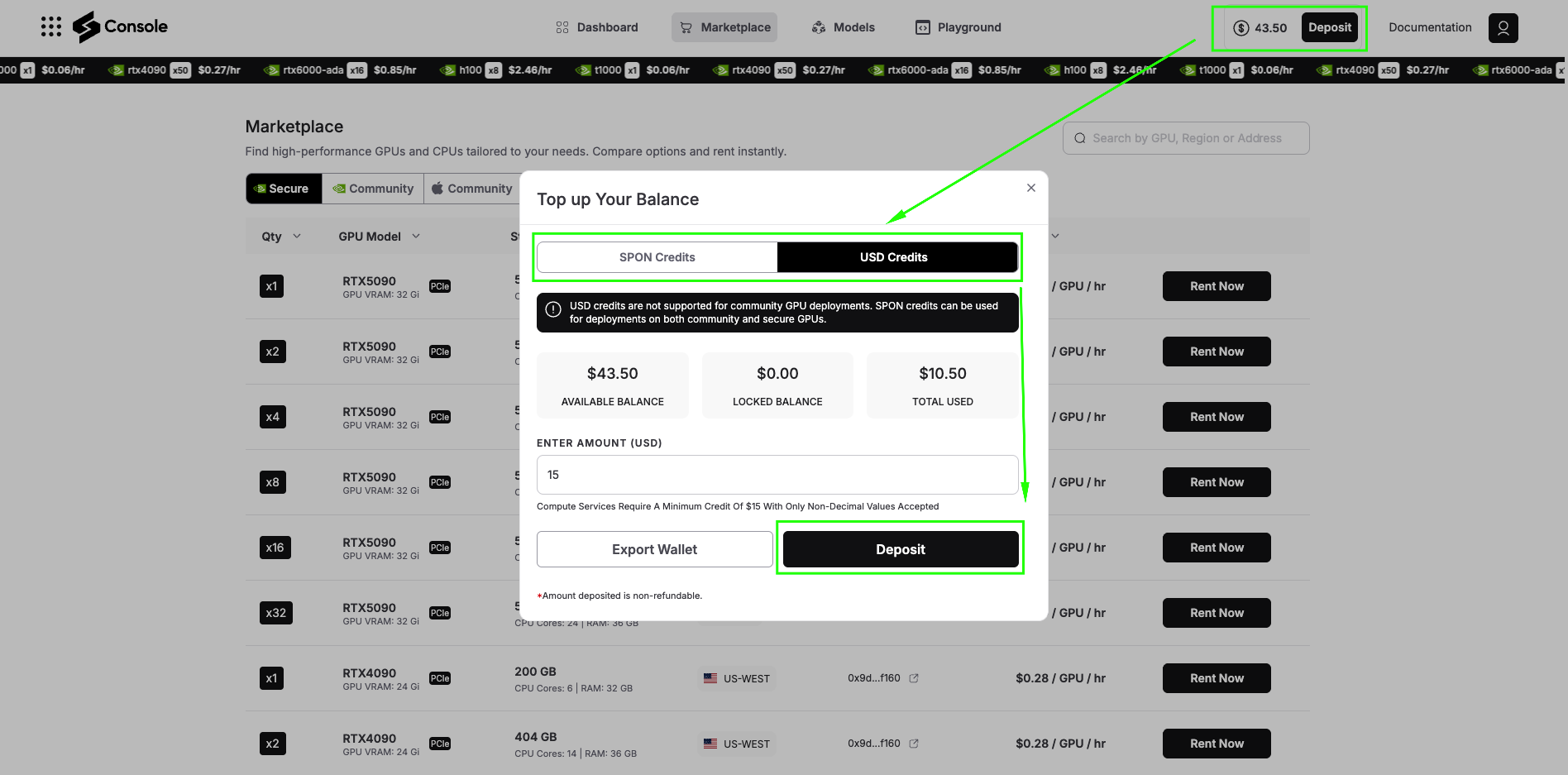
SPON Token: This is the native token of Spheron Network. When you deposit with SPON, you unlock the full power of the ecosystem. SPON credits can be used on both:
-
Community GPUs: Lower-cost GPU resources powered by community Fizz Nodes (personal machines and home setups)
-
Secure GPUs: Data center-grade GPU providers offering enterprise reliability
USD Credits: With USD deposits, you can deploy only on Secure GPUs. Community GPUs are not available with USD deposits.
For running Jina Code Embeddings 1.5B, we recommend starting with Secure GPUs to ensure consistent performance. Add sufficient credits to your account based on your expected usage.
Step 2: Navigate to GPU Marketplace
After adding credits, click on Marketplace. Here you’ll see two main categories:
Secure GPUs: These run on data center-grade providers with enterprise SLAs, high uptime guarantees, and consistent performance. Ideal for production workloads and applications that require reliability.
Community GPUs: These run on community Fizz Nodes, essentially personal machines contributed by community members. They’re significantly cheaper than Secure GPUs but may have variable availability and performance.
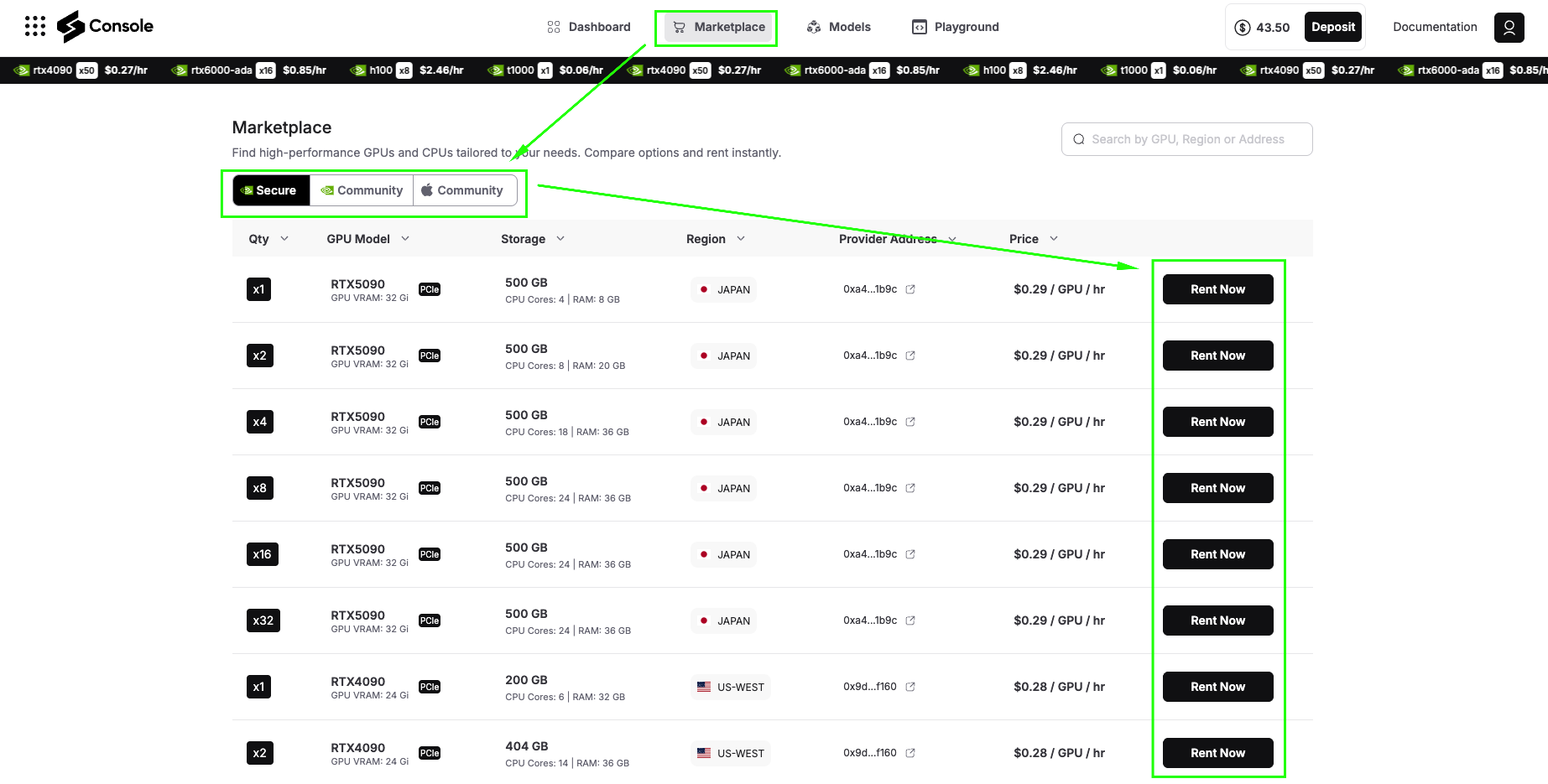
For this tutorial, we’ll use Secure GPUs to ensure smooth installation and optimal performance.
Step 3: Search and Select Your GPU
You can search for GPUs by:
-
Region: Find GPUs geographically close to your users
-
Address: Search by specific provider addresses
-
Name: Filter by GPU model (RTX 4090, A100, etc.)
For this demo, we’ll select a Secure RTX 4090 (or A6000 GPU), which offers
|
GPU VRAM: 24 Gi |
Storage: 404 GB | CPU Cores: 14 | RAM: 36 GB |
And excellent performance for running Jina Code Embeddings 1.5B. The 4090 provides the perfect balance of cost and capability for both testing and moderate production workloads.
Click Rent Now on your selected GPU to proceed to configuration.
Step 4: Select Custom Image Template
After clicking Rent Now, you’ll see the Rent Confirmation dialog. This screen shows all the configuration options for your GPU deployment. Let’s configure each section. Unlike pre-built application templates, running Jina Code Embeddings 1.5B requires a customized environment for development capabilities. Select the configuration as shown in the image below and click “Confirm” to deploy.
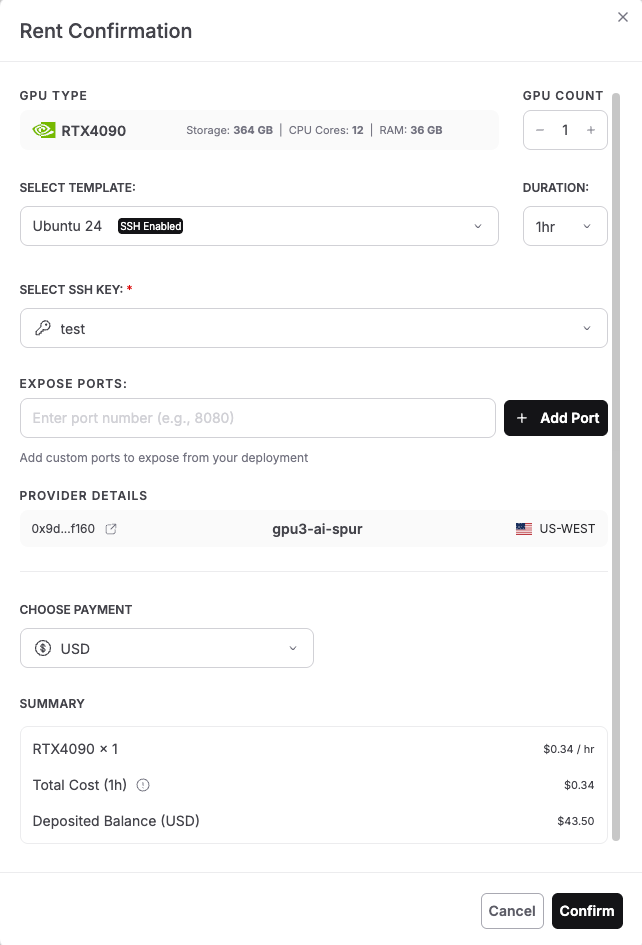
-
GPU Type: The screen displays your selected GPU (RTX 4090 in the image) with specifications: Storage, CPU Cores, RAM.
-
GPU Count: Use the + and – buttons to adjust the number of GPUs. For this tutorial, keep it at 1 GPU for cost efficiency.
-
Select Template: Click the dropdown that shows “Ubuntu 24” and look for template options. For running Jina Code Embeddings 1.5B, we need an Ubuntu-based template with SSH enabled. You’ll notice the template shows an SSH-enabled badge, which is essential for accessing your instance via terminal. Select: Ubuntu 24 or Ubuntu 22 (both work perfectly)
-
Duration: Set how long you want to rent the GPU. The dropdown shows options like: 1hr (good for quick testing), 8hr, 24hr, or longer for production use. For this tutorial, select 1 hour initially. You can always extend the duration later if needed.
-
Select SSH Key: Click the dropdown to choose your SSH key for secure authentication. If you haven’t added an SSH key yet, you’ll see a message to create one.
-
Expose Ports: This section allows you to expose specific ports from your deployment. For basic command-line access, you can leave this empty. If you plan to run web services or Jupyter notebooks, you can add ports.
-
Provider Details: The screen shows provider information:
This shows which decentralized provider will host your GPU instance.
-
Scroll down to the Choose Payment section. Select your preferred payment option:
-
USD – Pay with traditional currency (credit card or other USD payment methods)
-
SPON: Pay with Spheron’s native token for potential discounts and access to both Community and Secure GPUs
-
The dropdown shows “USD” in the example, but you can switch to SPON if you have tokens deposited.
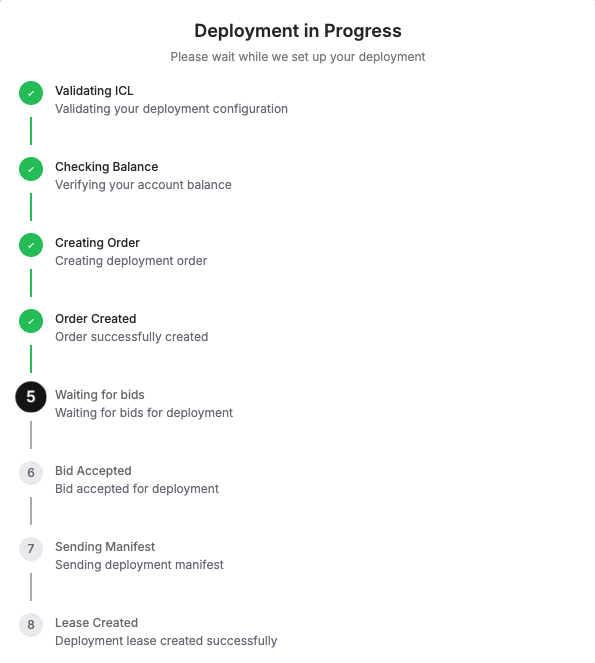
Step 5: Check the “Deployment in Progress“
Next, you’ll see a live status window showing every step of what’s happening, like: Validating configuration, Checking balance, Creating order, Waiting for bids, Accepting a bid, Sending manifest, and finally, Lease Created Successfully. Once this is complete, your Ubuntu server is live!
Deployment typically completes in under 60 seconds. Once you see “Lease Created Successfully,” your Ubuntu server with GPU access is live and ready to use!
Step 6: Access Your Deployment
Once deployment completes, navigate to the Overview tab in your Spheron console. You’ll see your deployment listed with:
-
Status: Running
-
Provider details: GPU location and specifications
-
Connection information: SSH access details
-
Port mappings: Any exposed services
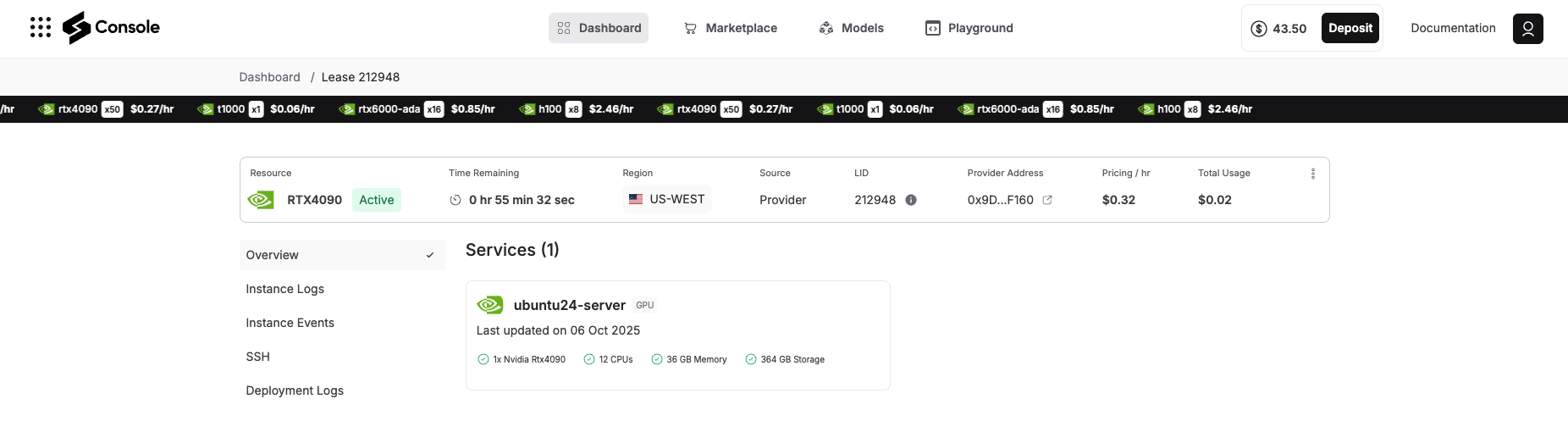
Step 7: Connect via SSH
Click the SSH tab, and you will see the steps on how to connect your terminal via SSH to your deployment details. It will look something like the image below, follow it:
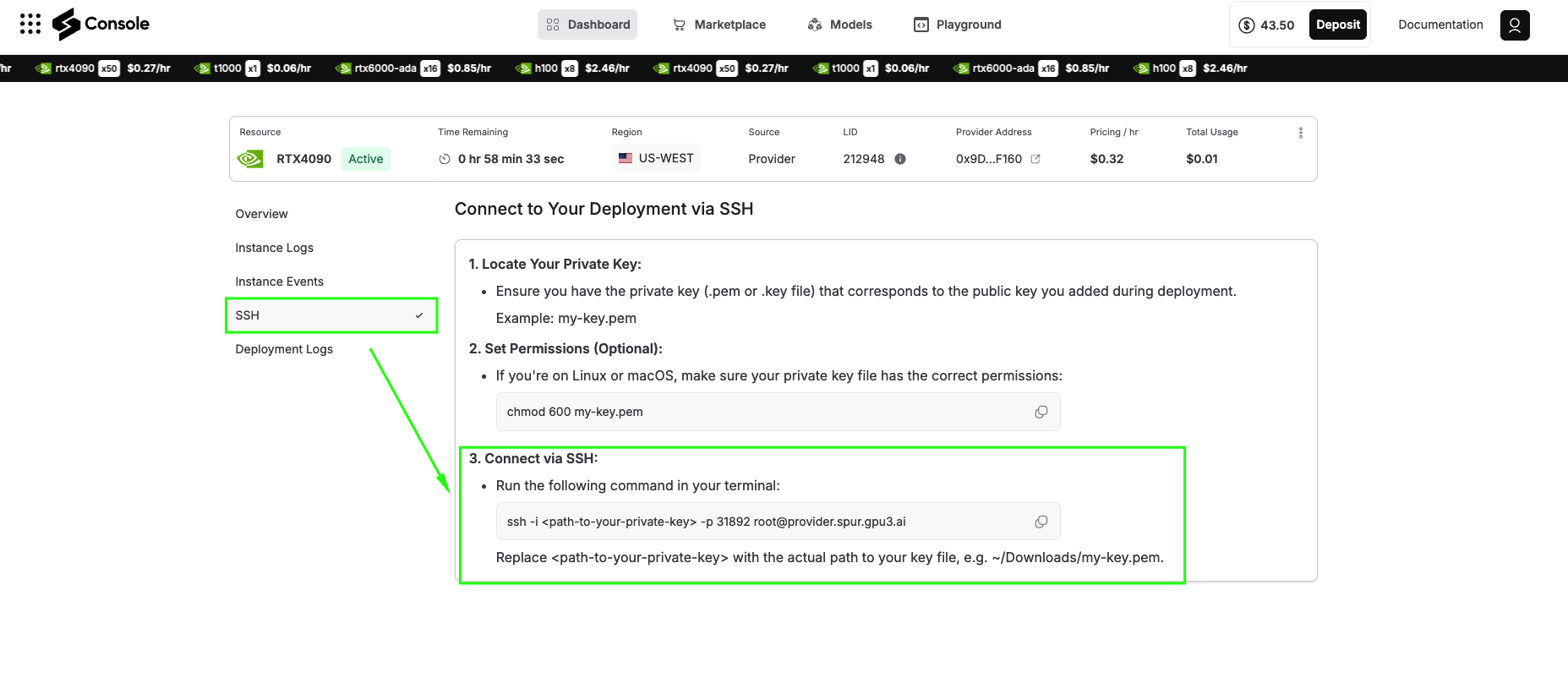
ssh -i -p root@
Open your terminal and paste this command. Upon your first connection, you’ll see a security prompt requesting that you verify the server’s fingerprint. Type “yes” to continue. You’re now connected to your GPU-powered virtual machine on the Spheron decentralized network.
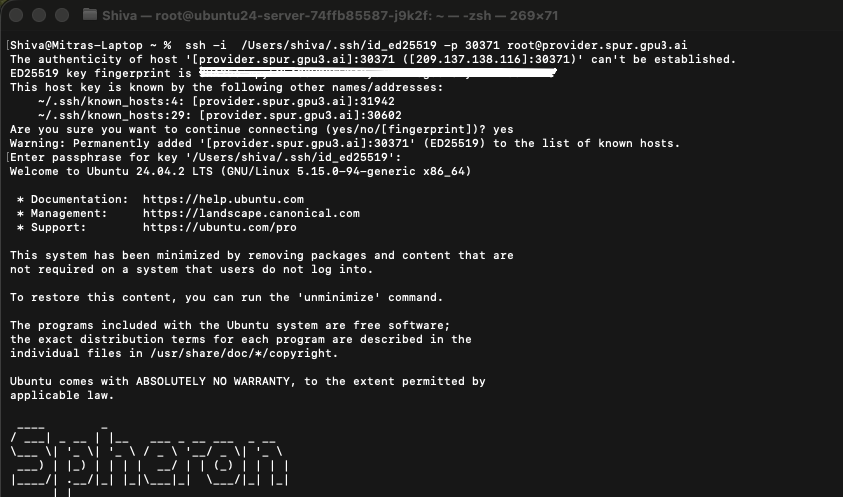
Software Environment Setup
Now we’ll build a Python environment specifically for running Jina Code Embeddings.
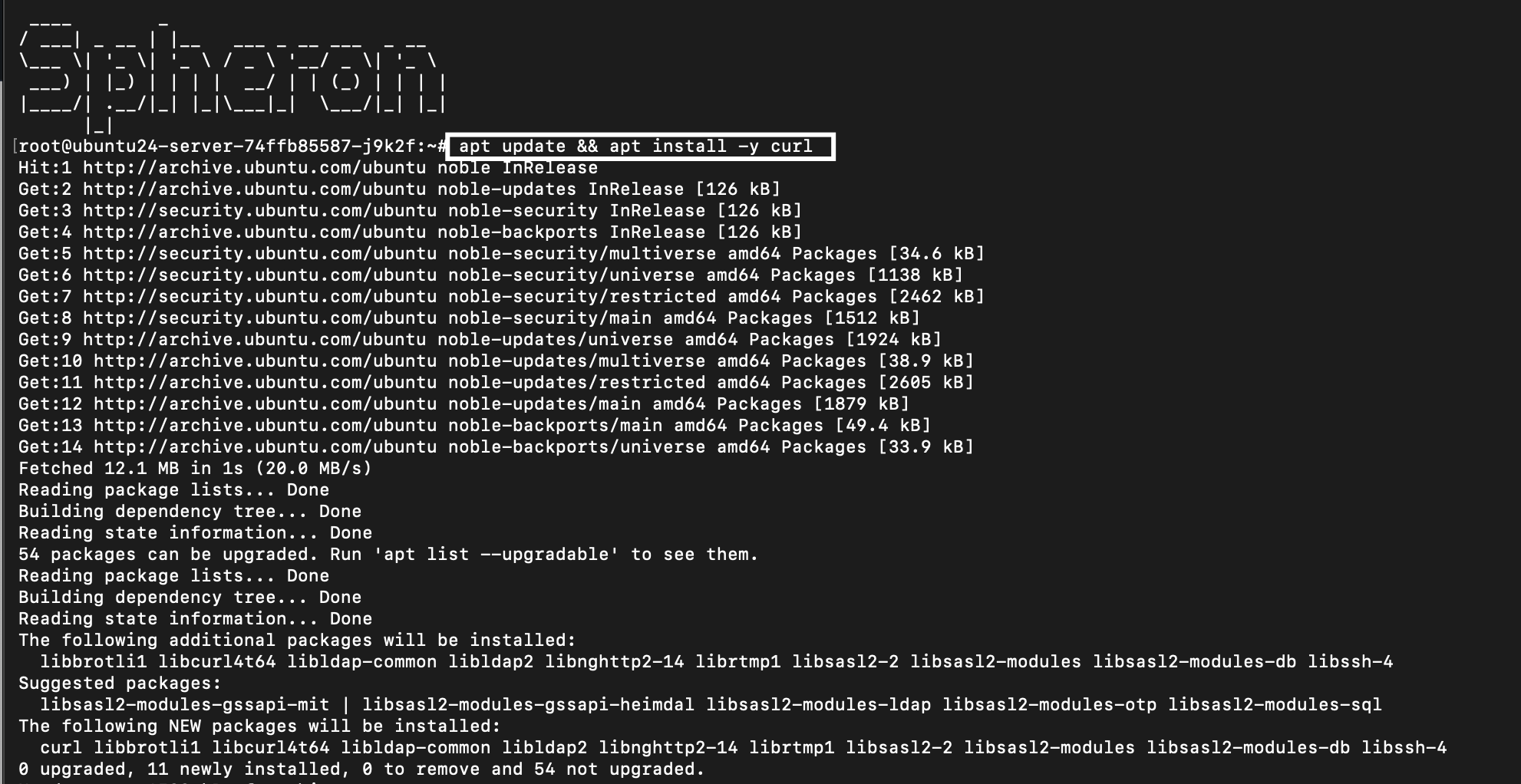
Step 8: Update System and Install Curl
First, update your system packages and install curl, which we’ll use for downloading dependencies:
apt update && apt install -y curl
Verify curl installation:
curl --version
You should see output showing curl version information, confirming it’s properly installed.

Step 9: Install Python and Pip
Install Python’s package manager (pip):
curl -O https://bootstrap.pypa.io/get-pip.py
apt update && apt install -y python3-pip
Verify pip and Python installation:
pip3 --version
python3 --version
You should see output like: pip 24.0 from /usr/lib/python3/dist-packages/pip (python 3.12) and Python 3.12.3
Step 10: Install Python Virtual Environment Tools
Install the virtual environment module for Python 3.12:
apt install -y python3.12-venv
This package allows you to create isolated Python environments, preventing dependency conflicts between different projects.
Step 11: Create and Activate Virtual Environment
Create a virtual environment named “Jina” and activate the virtual environment:
python3.12 -m venv Jina
source Jina/bin/activate
After activation, your command prompt changes to show (Jina) at the beginning, indicating you’re working inside the virtual environment. Any packages you install now will be isolated from the system Python installation.

Step 12: Install Core Python Dependencies
Install the fundamental packages for running the model:
python -m pip install "sentence-transformers>=5.0.0" "torch>=2.7.1"
This command installs:
Sentence-Transformers (≥5.0.0): A high-level library that simplifies loading and using embedding models. It handles tokenization, batching, and device management and provides convenient encoding methods.
PyTorch (≥2.7.1): The underlying deep learning framework. This version includes optimizations for modern CUDA versions and improved memory efficiency for running large models.
The installation takes 5-10 minutes as it downloads PyTorch (~2GB) and sentence-transformers with their dependencies.
Install the wheel package for building Python packages:
pip install wheel
Step 13: Install CUDA Toolkit
Install NVIDIA CUDA toolkit for GPU acceleration:
apt install -y nvidia-cuda-toolkit
This installs the complete CUDA development environment, including:
After installation, create symbolic links for CUDA libraries:
ln -s /usr/lib/x86_64-linux-gnu/libcuda* /usr/lib/cuda/lib64/ 2>/dev/null

This command creates symbolic links from the system CUDA libraries to the standard CUDA library path. The 2>/dev/null Suppresses any errors if some links already exist. This step ensures that Python packages can find the CUDA libraries when compiling GPU-accelerated code.
Step 14: Install FlashAttention-2
FlashAttention-2 is an optimized attention mechanism that significantly speeds up model inference. Install it with:
python -m pip install flash-attn --no-build-isolation
Important Notes:
-
This installation compiles CUDA kernels from source and takes a few minutes if the requirements are not already satisfied
-
The
--no-build-isolationThe flag allows the installer to use your environment’s packages -
You’ll see compilation progress messages; this is normal
-
The process uses significant disk space temporarily
If this step fails with CUDA-related errors, don’t worry, you can still run the model with standard attention (slightly slower but fully functional). The model will automatically fall back to SDPA (Scaled Dot Product Attention) if FlashAttention isn’t available.
Step 15: Install Git
Install Git for version control and cloning repositories:
apt update && apt install -y git
Git is useful if you need to clone code repositories or manage your own scripts.
Step 16: Authenticate with Hugging Face
The Jina Code Embeddings model is hosted on Hugging Face Hub. Authenticate to it:
hf auth login
When prompted, paste your Hugging Face access token. If you don’t have a token yet:
-
Click “New token”
-
Select “Read” permissions (sufficient for downloading models)
-
Name it something memorable like “jina-embeddings”
-
Copy the token and paste it when the terminal prompts you
After successful authentication, you’ll see a confirmation message.
Step 17: Install Accelerate
Install the Accelerate library for optimized model loading and inference:
pip install accelerate
Accelerate is a Hugging Face library that simplifies:
-
Distributed training and inference
-
Mixed-precision computation (using bfloat16 for faster processing)
-
Multi-GPU management
-
Device placement optimization

Step 18: Connecting a Code Editor
While you can write Python scripts directly in the terminal using editors like nano or vim, connecting a modern code editor dramatically improves productivity. We recommend VS Code, Cursor, or any IDE supporting SSH remote development.
This workflow feels exactly like local development, but executes everything on your powerful GPU virtual machine.
Running Basic Examples
Let’s start with a simple script that demonstrates core functionality.
Script 1: Simple Text-to-Code Retrieval
Create a file named test_jina.py:
import torch
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"jinaai/jina-code-embeddings-1.5b",
model_kwargs={
"torch_dtype": torch.bfloat16,
"attn_implementation": "flash_attention_2",
"device_map": "cuda"
},
tokenizer_kwargs={"padding_side": "left"},
)
queries = [
"print hello world in python",
"initialize array of 5 zeros in c++"
]
documents = [
"print('Hello World!')",
"int arr[5] = {0, 0, 0, 0, 0};"
]
query_embeddings = model.encode(queries, prompt_name="nl2code_query")
document_embeddings = model.encode(documents, prompt_name="nl2code_document")
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
How It Works:
The script loads the model with three important configurations:
bfloat16 precision: Uses 16-bit brain floating point format instead of 32-bit floats. This halves memory usage and speeds up computation with minimal impact on accuracy. Modern GPUs (such as the A100 and RTX 40-series) have specialized hardware for bfloat16 math.
flash_attention_2: Activates the optimized attention mechanism we installed earlier. If this fails, the model automatically falls back to standard attention.
device_map="cuda": Places the model on your GPU. Without this, it runs on the CPU (much slower).
The tokenizer_kwargs={"padding_side": "left"} Setting is crucial. The model uses last-token pooling, so padding must occur on the left to ensure the last token always contains meaningful information.
We encode queries and documents separately with different prompts (nl2code_query vs nl2code_document). The model was trained with these prompts to distinguish between queries and documents, improving retrieval accuracy.
The similarity matrix is 2×2, where each cell shows how similar a query is to a document:
Query 0 vs Doc 0: 0.7670 (high—correct match)
Query 0 vs Doc 1: 0.1117 (low—different)
Query 1 vs Doc 0: 0.0938 (low—different)
Query 1 vs Doc 1: 0.6607 (high—correct match)
Run the script:
python3 test_jina.py
First run downloads the model (~3GB), which takes a few minutes. Subsequent runs use the cached version and execute quickly.

Advanced Testing Script
The second script demonstrates comprehensive testing across all supported tasks with challenging examples.
Script 2: Multi-Task Benchmark
Create test_jina_hard.py with the extensive code provided below.
import os
import math
import textwrap
import torch
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
# -----------------------------
# Config
# -----------------------------
USE_FLASH_ATTN = False # set True if you installed flash-attn successfully
DTYPE = torch.bfloat16
DEVICE_MAP = "cuda" # "auto" or "cpu" if you must
TRUNCATE_TO = 256 # Matryoshka test: set to None to disable
# -----------------------------
# Loader
# -----------------------------
model = SentenceTransformer(
"jinaai/jina-code-embeddings-1.5b",
model_kwargs={
"dtype": DTYPE,
"attn_implementation": "flash_attention_2" if USE_FLASH_ATTN else "sdpa",
"device_map": DEVICE_MAP,
},
tokenizer_kwargs={"padding_side": "left"},
)
# -----------------------------
# Helpers
# -----------------------------
def norm(a):
return F.normalize(torch.as_tensor(a), p=2, dim=1)
def cos_sim(a, b):
return norm(a) @ norm(b).t()
def pretty_topk(sim, queries, docs, k=3, title=""):
print(f"\n=== {title} (top-{k}) ===")
for i, q in enumerate(queries):
row = sim[i]
scores, idx = torch.topk(row, k=min(k, row.shape[0]))
print(f"\nQ{i+1}: {q[:100]}{'...' if len(q)>100 else ''}")
for rank, (s, j) in enumerate(zip(scores.tolist(), idx.tolist()), 1):
print(f" {rank}. {s:.4f} -> D{j+1}: {docs[j][:120]}{'...' if len(docs[j])>120 else ''}")
def print_matrix(sim, title="similarity"):
print(f"\n=== {title} matrix ({sim.shape[0]} x {sim.shape[1]}) ===")
with torch.no_grad():
for i in range(sim.shape[0]):
row = " ".join(f"{v:.3f}" for v in sim[i].tolist())
print(row)
def encode_with_prompt(texts, prompt_name):
# sentence-transformers handles batching internally
return model.encode(texts, prompt_name=prompt_name)
def maybe_truncate(emb, dims):
if dims is None:
return emb
t = torch.as_tensor(emb)
if t.shape[1] < dims:
raise ValueError(f"Embedding dim {t.shape[1]} < truncate_to {dims}")
return t[:, :dims]
# -----------------------------
# Datasets (harder / tricky)
# -----------------------------
# 1) NL2CODE — ambiguous wording, traps, and very similar distractors
nl2code_queries = [
# regex vs string contains; multi-lang trap
"python: find emails in a string (RFC-ish, not exact), return all matches",
# off-by-one and mutable default pitfalls
"python: create a function memo_fib(n) using lru_cache, handle n<=2 as base case",
# async + rate limit
"python: concurrently fetch JSON from 10 URLs with timeout and 5 req/s cap; retry failed once",
# c++ tricky zero-init vs value-init of vector
"c++: create vector of length 5 filled with zeros (no loop), idiomatic",
]
nl2code_docs = [
# good-enough regex (simplified), returns matches
"import re\ns="Contact: a@b.com, c.d+e@x.io"\nprint(re.findall(r'[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}', s))",
# wrong: only single match with search, not all
"import re\ns="x@y.z x2@y2.z2"\nprint(re.search(r'\\w+@\\w+\\.\\w+', s)) # only first match",
# correct lru_cache memo fib
"from functools import lru_cache\n@lru_cache(None)\ndef fib(n:int)->int:\n if n<=2: return 1\n return fib(n-1)+fib(n-2)",
# async with rate limit (token bucket-ish sketch)
textwrap.dedent("""\
import asyncio, aiohttp, time
SEM = asyncio.Semaphore(5) # crude: 5 concurrent; separate rate cap below
async def fetch(session, url):
async with SEM:
async with session.get(url, timeout=5) as r:
return await r.json()
async def main(urls):
out, t0, burst = [], time.time(), 0
async with aiohttp.ClientSession() as s:
for i, u in enumerate(urls):
# naive 5 req/sec limiter
now = time.time()
elapsed = now - t0
if burst >= 5 and elapsed < 1:
await asyncio.sleep(1 - elapsed); t0 = time.time(); burst = 0
out.append(asyncio.create_task(fetch(s, u)))
burst += 1
return await asyncio.gather(*out, return_exceptions=True)
"""),
# C++ value-init vector of zeros
"std::vector v(5); // value-initialized to 0",
# WRONG: reserves capacity only
"std::vector v; v.reserve(5); // NOT initialized to zeros"
]
# 2) CODE2CODE — equivalent implementations with subtle style/complexity differences
code2code_queries = [
"Python: breadth-first search on adjacency list graph; return shortest path distances from source",
"C++: deduplicate a vector while preserving original order (no set), O(n) average",
]
code2code_docs = [
# BFS correct
textwrap.dedent("""\
from collections import deque, defaultdict
def bfs(n, edges, src):
g = defaultdict(list)
for u,v in edges:
g[u].append(v); g[v].append(u)
dist = [-1]*n
dist[src]=0
dq=deque([src])
while dq:
u=dq.popleft()
for w in g[u]:
if dist[w]==-1:
dist[w]=dist[u]+1
dq.append(w)
return dist
"""),
# DFS (wrong for BFS distance)
textwrap.dedent("""\
def dfs(n, edges, src):
g = {i: [] for i in range(n)}
for u, v in edges: g[u].append(v); g[v].append(u)
dist = [-1]*n
def go(u, d):
if dist[u]!=-1: return
dist[u]=d
for w in g[u]: go(w, d+1)
go(src, 0)
return dist # not true BFS distances on graphs with multiple paths
"""),
# C++ stable unique using unordered_set + seen order
textwrap.dedent("""\
#include
#include
template
std::vector dedup_preserve(const std::vector& a) {
std::unordered_set seen;
std::vector out; out.reserve(a.size());
for (const auto& x: a) {
if (!seen.count(x)) { seen.insert(x); out.push_back(x); }
}
return out;
}
"""),
# WRONG: std::set reorders
textwrap.dedent("""\
#include
#include
template
std::vector dedup_resorted(const std::vector& a) {
std::set s(a.begin(), a.end());
return std::vector(s.begin(), s.end()); // order lost
}
"""),
]
# 3) CODE2NL — summarize code intent; include distractors
code2nl_queries = [
"Explain what this function does in one line: returns False on non-palindromes ignoring non-alnum.",
"Explain (short): function safely loads JSON file and returns default on error.",
]
code2nl_docs = [
"import re\ndef is_pal(s):\n t="".join(ch.lower() for ch in s if ch.isalnum())\n return t == t[::-1]",
"import json\n\ndef load_json(path, default=None):\n try:\n with open(path) as f: return json.load(f)\n except Exception: return default",
# distractor: unrelated code
"def primes(n):\n out=[]\n for x in range(2,n+1):\n if all(x%p for p in range(2,int(x**0.5)+1)): out.append(x)\n return out",
]
# 4) CODE2COMPLETION — continuations with misleading near-misses
code2completion_queries = [
"Python: given start of function to compute moving average with window=3, fill the rest efficiently",
"C++: given partial class with RAII file handle, complete destructor and move semantics safely",
]
code2completion_docs = [
# good completion (vectorized-ish)
textwrap.dedent("""\
def movavg3(a):
if len(a)<3: return []
return [(a[i]+a[i+1]+a[i+2])/3 for i in range(len(a)-2)]
"""),
# naive O(n*w) loop (acceptable but slower)
textwrap.dedent("""\
def movavg3(a):
out=[]
for i in range(len(a)-2):
out.append((a[i]+a[i+1]+a[i+2])/3)
return out
"""),
# C++ RAII file wrapper (sketch)
textwrap.dedent("""\
#include
struct File {
std::FILE* f = nullptr;
explicit File(const char* path, const char* mode) : f(std::fopen(path, mode)) {}
~File(){ if(f) std::fclose(f); }
File(File&& o) noexcept : f(o.f){ o.f=nullptr; }
File& operator=(File&& o) noexcept {
if(this!=&o){ if(f) std::fclose(f); f=o.f; o.f=nullptr; }
return *this;
}
File(const File&)=delete;
File& operator=(const File&)=delete;
};
"""),
# WRONG: leaks or double-close
textwrap.dedent("""\
struct FileBad {
std::FILE* f = nullptr;
~FileBad(){ std::fclose(f); } // no null check
};
"""),
]
# 5) QA — technical Q&A with distractors
qa_queries = [
"In Python, what's the most reliable way to zero-copy share a NumPy array with PyTorch on GPU?",
"In SQL, how do you prevent SQL injection when building search queries with user input?",
]
qa_docs = [
# correct-ish: use torch.from_numpy + pin memory or to(device); zero-copy CPU->Torch, GPU requires .to('cuda')
"Use torch.from_numpy(arr) for zero-copy CPU sharing; then move to GPU via .to('cuda', non_blocking=True) after pin_memory().",
# distractor
"Convert NumPy array to list and rebuild the tensor using torch.tensor(list(arr)) # copies data twice.",
# SQL parameterization
"Use parameterized queries / prepared statements (e.g., psycopg2 placeholders, SQLAlchemy bound params); never string-concatenate.",
# distractor
"Escape quotes manually and concatenate user input into the SQL string.",
]
# -----------------------------
# Runner per task
# -----------------------------
def run_task(name, q, d, q_prompt, d_prompt, k=3):
q_emb = encode_with_prompt(q, q_prompt)
d_emb = encode_with_prompt(d, d_prompt)
sim_full = cos_sim(q_emb, d_emb)
print_matrix(sim_full, title=f"{name} (full {q_prompt} vs {d_prompt})")
pretty_topk(sim_full, q, d, k=k, title=f"{name} top-{k} (full-dim)")
if TRUNCATE_TO:
q_tr = maybe_truncate(q_emb, TRUNCATE_TO)
d_tr = maybe_truncate(d_emb, TRUNCATE_TO)
sim_tr = cos_sim(q_tr, d_tr)
pretty_topk(sim_tr, q, d, k=k, title=f"{name} top-{k} ({TRUNCATE_TO}D Matryoshka)")
# quick Kendall tau-like stability (very rough): compare argmax per row
stable = 0
for i in range(sim_full.shape[0]):
j_full = int(torch.argmax(sim_full[i]))
j_tr = int(torch.argmax(sim_tr[i]))
stable += (j_full == j_tr)
print(f"\n[{name}] Top-1 stability after truncation to {TRUNCATE_TO}D: {stable}/{sim_full.shape[0]} match\n")
# -----------------------------
# Execute all tasks
# -----------------------------
if __name__ == "__main__":
# NL2CODE
run_task(
"NL2CODE",
nl2code_queries,
nl2code_docs,
q_prompt="nl2code_query",
d_prompt="nl2code_document",
k=3
)
# CODE2CODE
run_task(
"CODE2CODE",
code2code_queries,
code2code_docs,
q_prompt="code2code_query",
d_prompt="code2code_document",
k=3
)
# CODE2NL
run_task(
"CODE2NL",
code2nl_queries,
code2nl_docs,
q_prompt="code2nl_query",
d_prompt="code2nl_document",
k=3
)
# CODE2COMPLETION
run_task(
"CODE2COMPLETION",
code2completion_queries,
code2completion_docs,
q_prompt="code2completion_query",
d_prompt="code2completion_document",
k=3
)
# QA
run_task(
"QA",
qa_queries,
qa_docs,
q_prompt="qa_query",
d_prompt="qa_document",
k=3
)
print("\nDone. If FlashAttention errors occur, set USE_FLASH_ATTN=False (default) to use SDPA.\n")
This script tests five different tasks:
NL2CODE Testing: Matches natural language descriptions to code, including tricky cases with:
-
Ambiguous wording that could match multiple implementations
-
Common pitfalls like mutable default arguments
-
Async operations with rate limiting
-
Language-specific idioms
CODE2CODE Testing: Finds similar implementations despite differences:
CODE2NL Testing: Matches code to natural language explanations, filtering out unrelated code snippets that might confuse simpler models.
CODE2COMPLETION Testing: Predicts what code should come next, distinguishing between correct continuations and plausible-but-wrong alternatives.
QA Testing: Answers technical questions by matching them to relevant documentation or code examples, with distractors that mention related concepts but don’t actually answer the question.
The script also demonstrates Matryoshka embeddings by truncating vectors to 256 dimensions and measuring whether top-1 matches remain stable. This quantifies the speed-vs-accuracy tradeoff you can make in production.
Run the comprehensive test:
python3 testjina2.py
You’ll see detailed output showing similarity matrices and top-k matches for each task. This helps you understand how the model behaves on your specific use cases and calibrate expectations.

Production Deployment Considerations
When moving from experimentation to production, consider:
Indexing Strategy
For large codebases, pre-compute embeddings offline and store them in a vector database like:
-
Qdrant: Open-source, high-performance, easy to deploy
-
Milvus: Scales to billions of vectors, excellent for massive datasets
-
Pinecone: Fully managed, requires no infrastructure maintenance
-
Weaviate: Combines vector and traditional search
API Design
Wrap the model in a FastAPI or Flask service with endpoints for:
-
Single query embedding
-
Batch embedding (more efficient)
-
Similarity search against your index
-
Health checks and monitoring
Caching
Implement caching for frequently-requested queries. Since embeddings are deterministic (the same input always produces the same output), aggressive caching significantly reduces compute costs.
Monitoring
Track:
-
Query latency (p50, p95, p99 percentiles)
-
GPU utilization and memory usage
-
Cache hit rate
-
Error rates and types
Scaling
As load increases:
-
Use multiple GPU instances behind a load balancer
-
Implement request batching to maximize GPU utilization
-
Consider quantization (int8) for further speedup
-
Separate indexing (write) and search (read) workloads
Conclusion
Jina Code Embeddings 1.5B provides a powerful foundation for code-related AI applications. Its compact size makes it cost-effective to run, while its specialized training delivers strong performance across diverse programming tasks. The Matryoshka embedding support offers unique flexibility; you can tune for speed, memory, or accuracy without changing models or retraining.
This guide walked you through the complete setup on a GPU virtual machine, from initial provisioning through running comprehensive tests. You now have a working environment for building code search engines, retrieval-augmented generation systems, code recommendation tools, or documentation generators.
Next steps to explore:
-
Integrate with your codebase and measure retrieval quality
-
Experiment with different Matryoshka dimensions for your specific use case
-
Add a lightweight re-ranker (like a cross-encoder) to boost top-k accuracy
-
Build a simple UI for your team to search code conversationally
-
Monitor performance metrics and optimize based on actual usage patterns
The model’s open availability and reasonable hardware requirements lower barriers to building sophisticated developer tools that were previously feasible only for large organizations with extensive ML infrastructure.